搜索






 Time:Jan 07, 2025
Time:Jan 07, 2025
I. Research Background:
All-solid-state batteries are garnering significant attention due to their distinct advantages over conventional liquid lithium-ion batteries, namely high energy density and enhanced safety. Among these, solid-state electrolytes, as core components of all-solid-state batteries, have emerged as a research hotspot in recent years. In the quest to identify solid-state electrolytes with high ionic conductivity, scientists have discovered that ab initio molecular dynamics simulations can accelerate the discovery of fast ionic conductors. However, these methods entail high computational costs, hindering large-scale application and necessitating novel technical approaches to address this challenge. In recent years, machine learning (ML) has demonstrated immense potential in accelerating novel material discovery, optimising manufacturing processes, and predicting battery cycle life. Nevertheless, material datasets are typically small (containing only hundreds of lithium-ion conductors) and often highly diverse, posing significant challenges for training reliable models and constituting a key obstacle in accelerating material discovery. Addressing this issue, semi-supervised learning methods offer novel approaches to tackling the small-sample problem. In research, labelled data is often scarce and costly to acquire, whereas unlabelled data is typically more abundant. By leveraging the rich unlabelled data available in inorganic crystal structure databases alongside the limited labelled data, this approach compensates for the data requirements of traditional supervised learning, significantly enhancing model performance and generalisation capabilities.
II. Brief Overview of Research Work
This work developed a semi-supervised learning framework integrating consistency regularisation and pseudo-labelling, named ‘XRDMatch’. This framework utilises only X-ray diffraction patterns as descriptors, requiring no additional information. By leveraging the abundant unlabelled data within inorganic crystal structure databases to augment limited labelled data, this approach facilitates the construction of accurate and robust models. The integrated learning strategy achieves an F1 score of 0.92. Further predictions on unlabelled data identified 38 superionic conductors, 32 of which were validated by recent literature reports, while 6 novel candidate materials were verified through ab initio molecular simulations. Among these, Li₆AsSe₅I was subsequently synthesised and experimentally confirmed as a fast ionic conductor. This work underscores the viability of semi-supervised learning frameworks in overcoming data scarcity constraints, highlighting the model's significant potential for efficiently discovering room-temperature superionic conductors.
III. Core Content Presentation Section
Model Description: First, we employed the Pymatgen software package to compute XRD patterns from labelled and unlabelled crystal data collected in Step 1 of Figure 1, generating 4501-dimensional vectors for each diffraction pattern. Subsequently, all XRD data underwent normalisation processing. The data augmentation process was divided into labelled and unlabelled data streams, as depicted in Step 2 of Figure 1. From a materials scientist's perspective, weak augmentation preserves the fundamental structure of XRD patterns while introducing minor perturbations simulating measurement noise or slight variations in experimental conditions. Conversely, strong augmentation significantly alters XRD patterns to mimic more pronounced changes, such as those potentially arising from substantial compositional or structural shifts. For labelled samples, weak data augmentation represents subtle transformations with minimal impact on the data's inherent properties, thereby generating diverse samples. For unlabelled data, our approach incorporates consistency regularisation, a method that predicts a given sample using both weak and strong augmentation techniques. The objective is to ensure consistency in predictions across varying intensities and perturbations, thereby guiding the model to learn more robust and consistent feature representations on unlabelled data. Given data scarcity, we selected the VGG-11 network for feature extraction. The VGG Net architecture is depicted in Figure 1, Step 3. Subsequently, we train a deep convolutional neural network model using the labelled data stream dataset to initialise network parameters. The unlabelled data stream predicts weakly and strongly augmented datasets based on the model trained on the labelled dataset, as depicted in Step 3 of Figure 1. For the supervised model component, we selected cross-entropy loss as the objective function to guide the model in learning correct classification tasks on labelled data. For the unsupervised model component, weaker perturbations in weakening induce more robust preliminary predictions. Through the weakening process, we obtained preliminary predictions for unlabelled data. Predictions exceeding a predetermined threshold were identified as ‘pseudo-labelled data’ and incorporated into the training set in subsequent iterations. Strong augmentations typically generate more diverse samples but with lower prediction confidence, aiding the model in expanding its decision boundary. Subsequently, a consistency loss is computed between these two predictions, ensuring coherence in feature representations and helping the model learn more robust and generalisable feature representations on unlabelled data, as depicted in Figure 1, Step 4. Finally, the loss formulation in XRDMatch is expressed as a combination of supervised loss Ls and unsupervised loss Lu weighted by α: L = Ls + α × Lu. Through the addition of pseudo labels and multiple iterations, the classification model progressively gains accuracy and robustness. Each iteration refines both the model's predictions and the pseudo-labels, ultimately enhancing performance and generalisation capability. This iterative approach leverages the model's growing knowledge to make increasingly informed predictions and adapt to the dataset's characteristics. Figure 2 presents our predictions for six fast-ion conductors using this model, with Li₆AsSe₅I selected for synthesis and electrochemical testing (Figure 3).
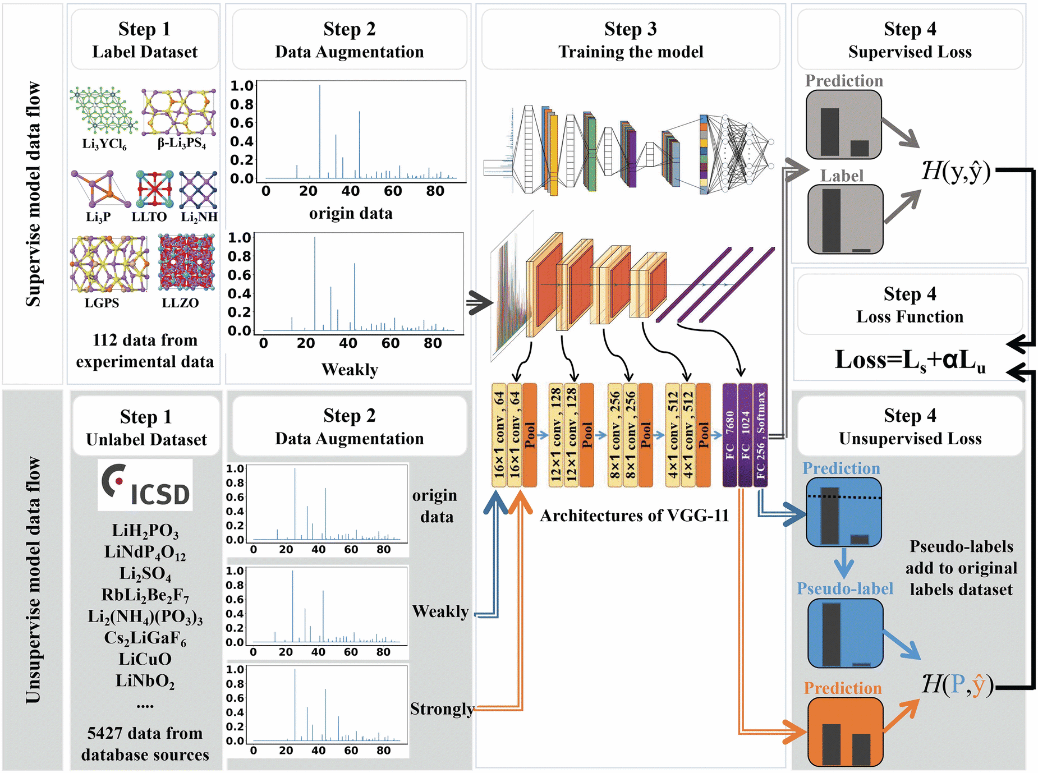
Figure 1. Comprehensive Flowchart of the XRDMatch Method
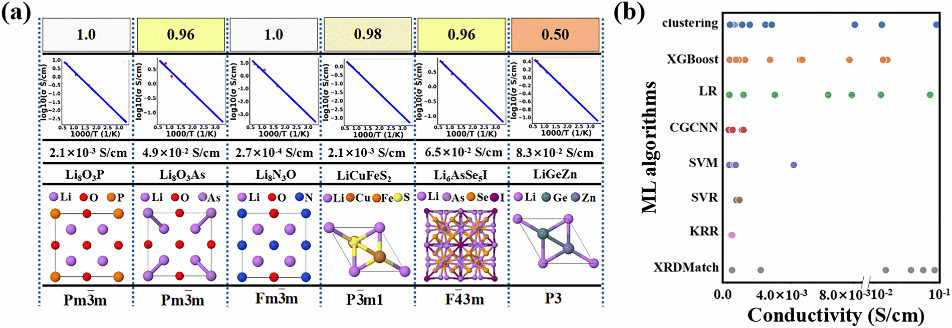
Figure 2. Evaluation of novel candidate materials via ab initio molecular dynamics (AIMD): (a) Six compounds with high similarity, including material similarity analysis, fitting plots of the Arrhenius relationship between log(σ) and temperature (T), and subsequent determination of unit cell parameters for follow-up materials. (b) Performance comparison between materials predicted by different machine learning methods and original data from the literature.
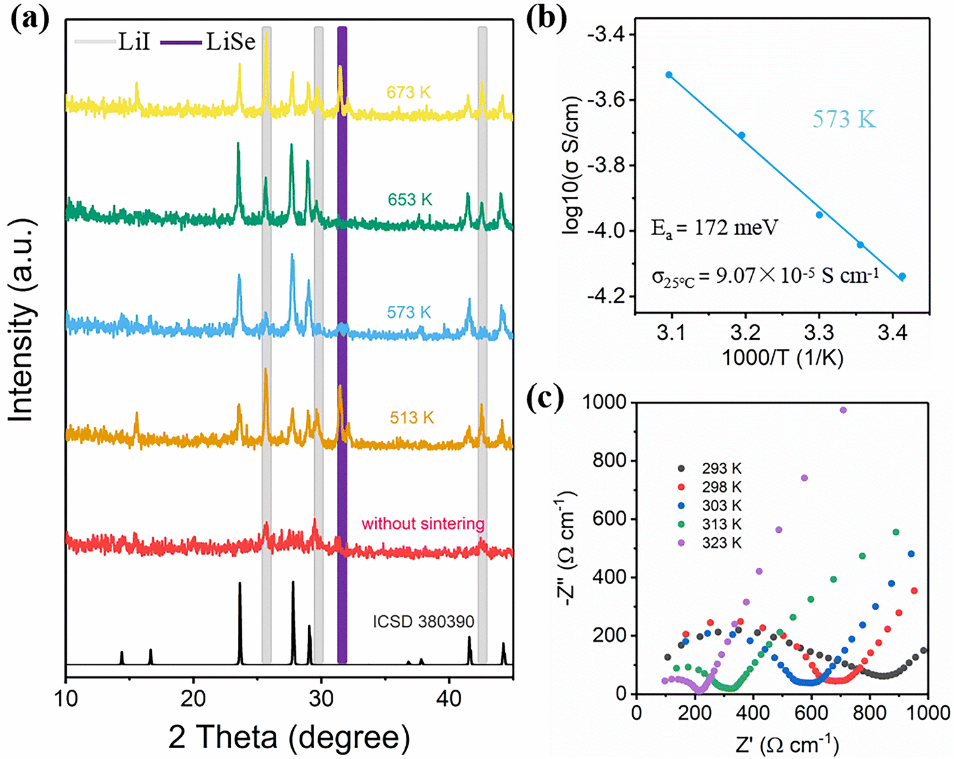
Figure 3. Experimental validation of predicted data: (a) X-ray diffraction patterns of Li₆AsSe₅I samples under different sintering conditions. (b) Arrhenius plot. (c) Electrochemical impedance spectra of samples at various temperatures.
IV. Conclusions and Outlook
Our innovative methodology marks a paradigm shift in predictive tasks within materials science. By fully leveraging the abundance of unlabelled data within materials databases, this approach effectively overcomes the limitations imposed by small, diverse datasets—a challenge particularly acute in this field. We anticipate that this pioneering learning paradigm will open new avenues for research, encompassing tasks such as phase identification, crystal size prediction, and space group determination for inorganic compounds. With the advent of autonomous laboratories, XRD patterns—as one of the most widely employed traditional material analysis techniques—can be seamlessly integrated into operational workflows to accelerate novel material development. Furthermore, the method's versatility extends to other characterisation data modalities, including Raman spectroscopy, nuclear magnetic resonance, and infrared spectroscopy.
This work is published in Energy & Environmental Science, a premier international journal in the energy field. First authors: Zheng Wan (PhD candidate, East China Normal University) and Zhenying Chen (postdoctoral researcher, Shanghai Jiao Tong University). Corresponding authors: Professor Xiao He and Associate Researcher Jinrong Yang (East China Normal University), alongside Professor Xiaodong Zhuang (School of Chemistry and Chemical Engineering, Shanghai Jiao Tong University; Centre for Innovation in Synthetic Science, Zhangjiang Advanced Research Institute).
Original link: https://doi.org/10.1039/D4EE02970D
This work was supported by the National Natural Science Foundation of China (NSFC), the Ministry of Science and Technology of China (Key R&D Programme), the Shanghai Municipal Science and Technology Commission, and JKW funding.
Author: Zhuang Xiaodong Group
Contributing Unit: Centre for Innovation in Synthetic Science
Research Centers
Research Capacity
m² Total Area
Building Complexes
沪交ICP备201251287 Copyright © 2025 ZIAS
 Address:No.1308 Keyuan Road, Pudong District, Shanghai
Address:No.1308 Keyuan Road, Pudong District, Shanghai
 Phone:86-21-54740000
Phone:86-21-54740000
 E-mail:zias@sjtu.edu.cn
E-mail:zias@sjtu.edu.cn
